Google BigQuery is one of the most popular and powerful cloud-based analytics solutions on the market. Google is constantly optimizing and enriching BigQuery’s capabilities and performance and this is always noticed in every Google NEXT conference.
As powerful as BigQuery is there are certain elements to be considered as best practices while interacting with it. Whether you’re building a data warehouse, ML models, analysis or just for storage. All of these considerations serve two main aspects:
Performance and Cost Control. To start working with BigQuery you need to load your data into it first, which means you’ll be using it as storage as well, then you’ll query this data somehow to create your models or create reports/visuals. In the next section, we’ll discuss best practices for these main actions loading, querying and storing.
Good Governance Enhances the Automated Import Benefit
BigQuery has become a cornerstone of data management and analysis in Google Cloud Platform, with important bridges to many Google data sets. You can set up automated export to BigQuery from:
- Google Analytics 360
- Google Analytics for Firebase
- Crashlytics
Similarly, the BigQuery Data Transfer Service allows you to set up automated BigQuery imports from:
- Campaign Manager
- Google Ads
- Google Ad Manager
- YouTube
- Google Play
- Google Cloud Storage
Loading Data into BigQuery
There are several aspects to consider before loading data into BQ, such as:
- Frequency: Depending on your business requirements you should select how frequently to load your data into BigQuery. The two ways are batch or streaming inserts. Batch inserts are free, but streaming inserts incur extra changes which is currently $0.05 per GB sent.
- Staging area or data source: Data can be loaded into BigQuery from Cloud Storage (recommended), Google services like Google Analytics, Google Ads and others, or uploaded from local machines.
- Files format: BigQuery supports the following formats when loading data Avro, JSON (newline delimited), CSV, Parquet and ORC. Some formats are faster than others as shown below.

- ETL or ELT?: when working with BigQuery it’s always recommended to use ELT over ETL. As data is getting bigger to the scale from terabytes to petabytes, and given the parallel processing capabilities that BQ offers. It’s more efficient to first load all the data into BigQuery then do your transformations on it, this way you don’t have to worry about scaling your ETL infrastructure to match the increasing amount of data, especially in high-velocity use cases. Another reason for preferring ELT over ETL is better support for exploratory data analysis. Once the data is loaded as is into BigQuery, we can always analyze it and find new patterns that could have been distorted if it has been cleaned before loading. We can still have both the clean and raw versions in BigQuery.
- Cloud Dataflow and Cloud Data Fusion are GCP products used for building ETL/ELT jobs which scales automatically for handling massive amounts of batch or streaming data and loading it into BigQuery.
- Another ETL tool/service is Cloud Dataprep which is an intelligent data service for visually exploring, cleaning, and preparing structured and unstructured data for analysis, reporting, and machine learning.
Querying BigQuery
Writing the best performing and most cost-efficient query can be a bit challenging if you don’t have substantial SQL experience. Here we’ll discuss some best practices to follow while writing a BQ query.
- BigQuery queries’ costs depend on the amount of data scanned, not the data retrieved.
- Control projection: projection is the number of columns you read when executing your query. You should always try to only select the columns you need, and avoid using “Select *” (aka select all) at all costs. Even if you use LIMIT clause it will not reduce the cost of the query.
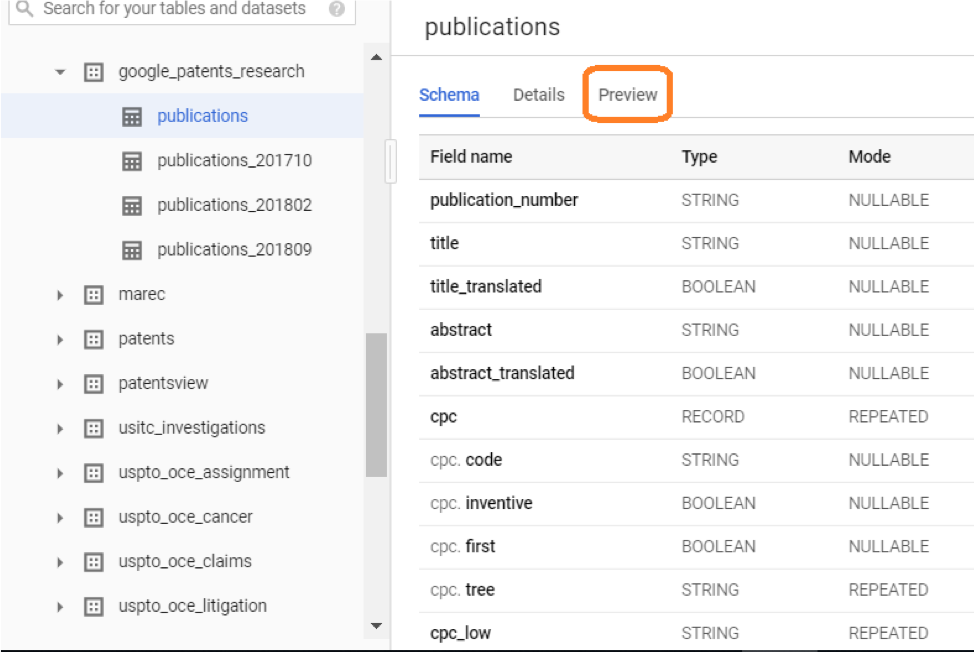
- If you need to explore the data before writing your query, use table preview option which is free.

- Always prefer partitioned tables (data or time partitioned) over sharded (date-named) tables.
- Reduce the number of data processed before joining other queries/tables.
- When querying wildcard tables, use the most granular prefix possible. Meaning if you have tables names like “TableName_YYYMMDD”, and you only need data from 2019, then use “TableName_2019*” and don’t use “TableName_*” then filter on year.
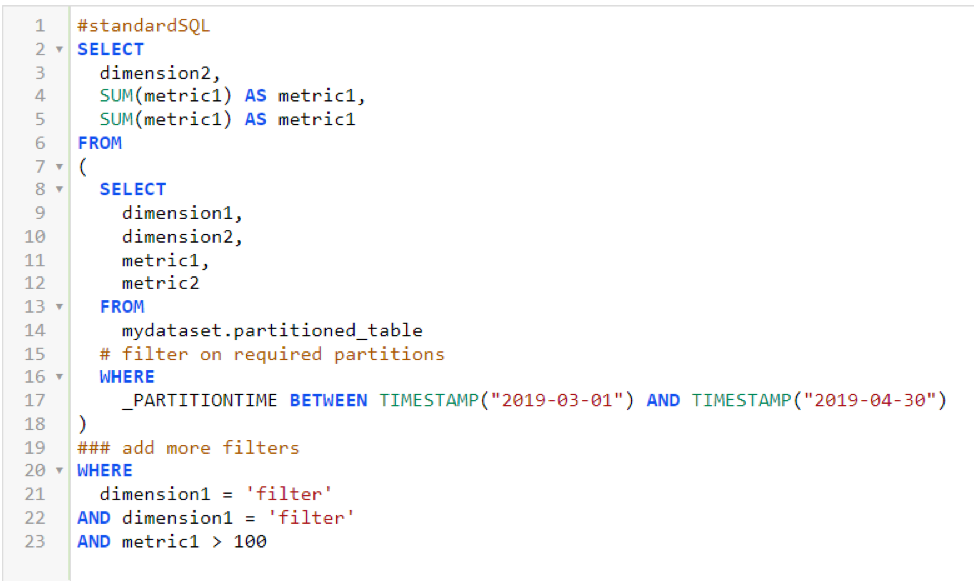
- When querying partitioned tables it’s recommended to first filter on the required parititions in the innermost select query, then add additional filters in outer queries as shown below.

- Avoid joining the same subquery several times in the same query. Instead try saving this subquery as an intermediate table querying it. Storage cost is much less than repetitive querying cost.
- Order By clause are very expensive, so unless really necessary try to limit your use of Order By clause as much as possible. Or just use it in the outermost query to sort results and not in subqueries.
- Avoid using JavaScript user-defined functions. If needed use native (SQL) UDFs instead.
- When joining two tables, start with the largest table for better performance.
- Do not use an external data source if you’re seeking better performance, unless it is a frequently changing data.
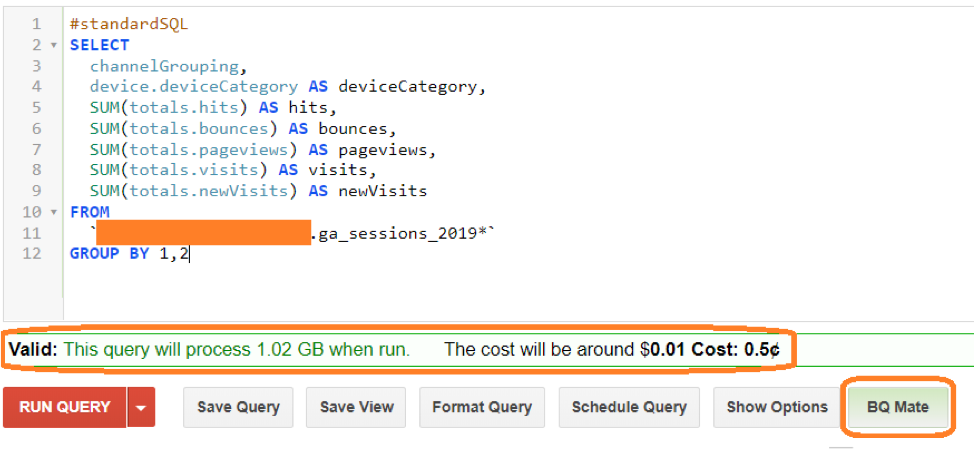
- Before executing your query check the query validator which will tell you approximately how much data will be scanned, so you can have an idea about how much it’ll cost using GCP Pricing calculator. Or simply use a third party addon like BQ mate which estimates query cost directly.

Managing Storage
Depending on the nature of your data and how much historical data you need to keep, you can optimize your storage for cost saving. Some of the best practices are:
- If you only need fresh data or recently updated data, and don’t care about historical data, you can set an expiration time for both tables or partitions. For example, setting partition expiration time to one month, this means that any partition older than one month will be automatically deleted. Keep in mind that this can’t be applied to existing tables/partitions, only to tables/partitioned created after the policy is set.
- BigQuery is natively optimized for cost reduction on the storage of data that is no longer actively queried. By default, any table/partition in BQ that is not touched for at least 90 days will be moved to what is called long-term storage, that costs $0.01 per GB per month which is 50% cheaper than normal rates. For even older data that you still need to maintain – in case you ever do need to query it, or just for general governance purposes – you have the option to export that data out of BigQuery into Google Cloud Storage for even lower-cost long-term storage.
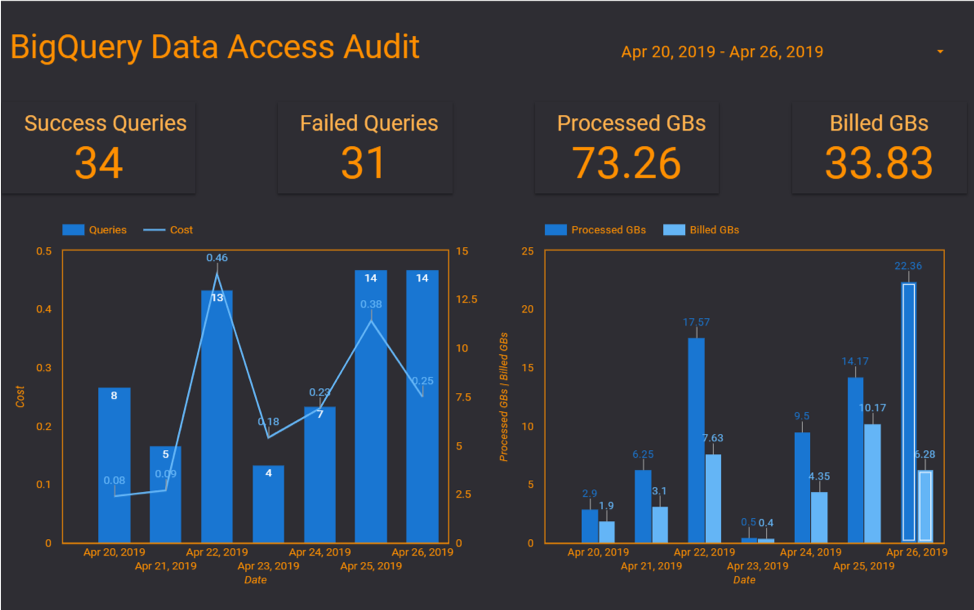
Monitor and Control Your Spend
Using Google’s Cloud export billing data to BigQuery functionality, you can monitor and even visualize up-to-date billing information for your whole GCP project, not only BigQuery.
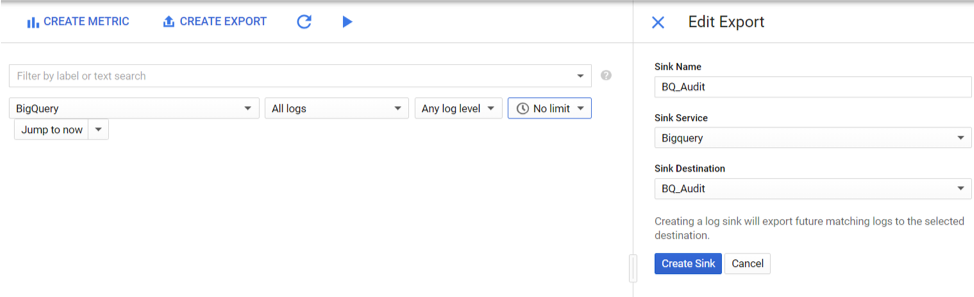
To create the export, navigate to the Stackdriver logs in the cloud console. Filter the logs using a filter of resource: BigQuery and logName: data_access. Then choose the Sink Service to be BigQuery and select a dataset or create a new one for the audit logs as shown below.
Once the data_access logs are being exported to BigQuery. You can create a view to clean up the data and include only columns needed for reporting. Some of the fields available in the export are:
- The actual Query
- Execution Timestamp
- Billing Tier
- Total Billed Bytes
- Total Processed Bytes
- Principal Email (User)
After collecting and cleaning up the access data, you can easily build reports and dashboards on top of it to monitor user’s usage and BigQuery spend on a daily or even hourly basis and start taking actions.
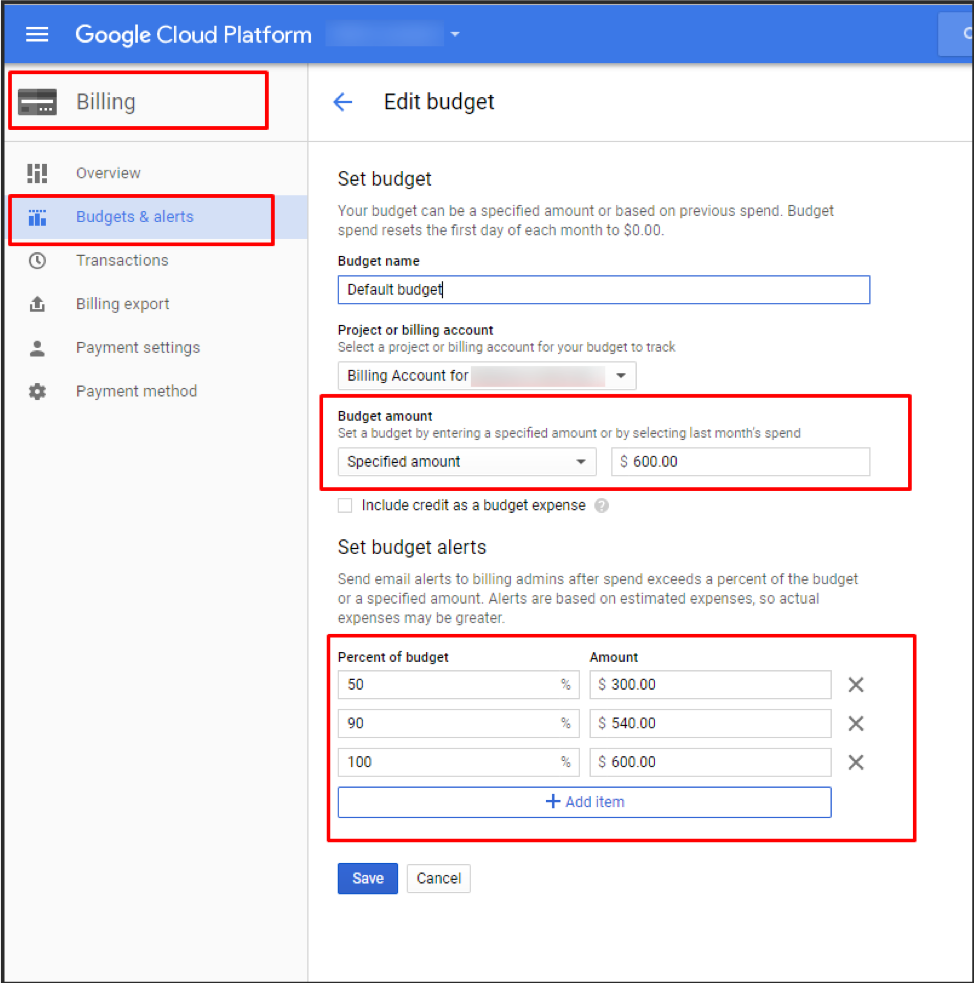
Another way for controlling and monitoring GCP spend is by setting a budget and budget alerts for your project or billing account as shown below. This is especially great for cases when you have several teams utilizing many GCP projects, such as BigQuery, Cloud Storage, Cloud Functions and more.

Mahmoud Taha
Data Engineering Team Lead, e-nor



